프로젝트 개선 과정
AI EXPO에 BLIP이라는 이름으로 출품했으나, 일정 관리와 팀 운영, 커뮤니케이션의 한계로 인해 서비스 완성 단계까지 도달하지 못하고 기능 중심의 발표에 그쳤습니다.
그러나 이 과정에서 여러 기업 관계자들로부터 피드백을 받으며 프로젝트의 실질적 가치와 시장성을 검증할 수 있었습니다.
이를 계기로 프로젝트를 재정비하며 협업 구조를 우선적으로 설계했습니다. 역할 분담을 명확히 정의하고, 정기 공유 프로세스와 이슈 트래킹 체계를 구축한 뒤 Meezy.로 리브랜딩하여 프로젝트를 재개했습니다.
해당 운영 구조를 기반으로 1월 5일 프로젝트를 다시 시작했으며, 기술 구현뿐만 아니라 협업 프로세스 개선까지 포함한 개발 경험을 체계적으로 확장했습니다.
이 경험을 통해 협업 구조 설계가 프로젝트 초기 단계에서 선행되어야 한다는 점을 인식하게 되었고, 이후 모든 프로젝트에서 커뮤니케이션 체계를 우선적으로 수립하는 방식으로 개발 프로세스를 개선하고 있습니다.
아키텍처
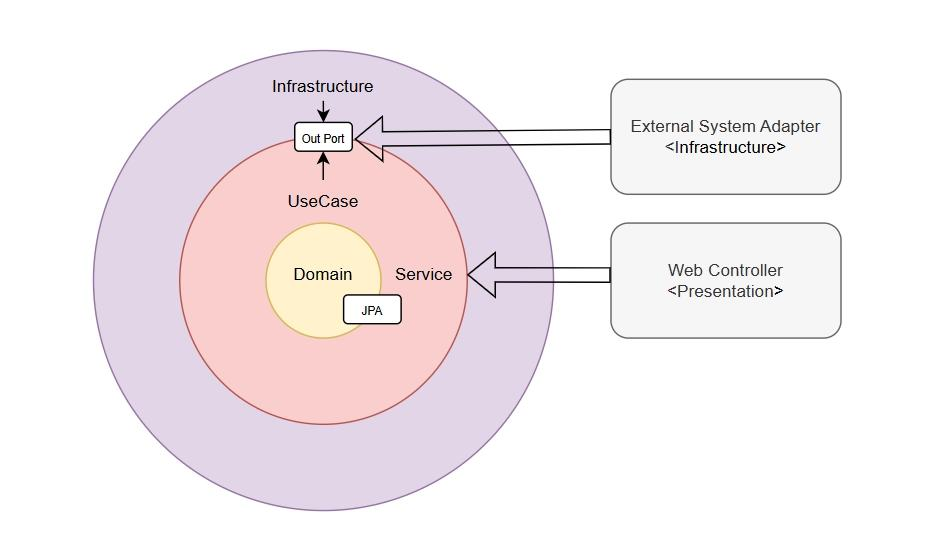
- Layered Architecture 기반, 변경 가능성이 높은 외부 인프라 영역에만 Out Port/Adapter 패턴을 선택적으로 적용
- 도메인 영역은 매퍼 계층의 반복적인 변환 비용을 제거하고 비즈니스 로직에 집중하기 위해 JPA 종속 설계를 수용
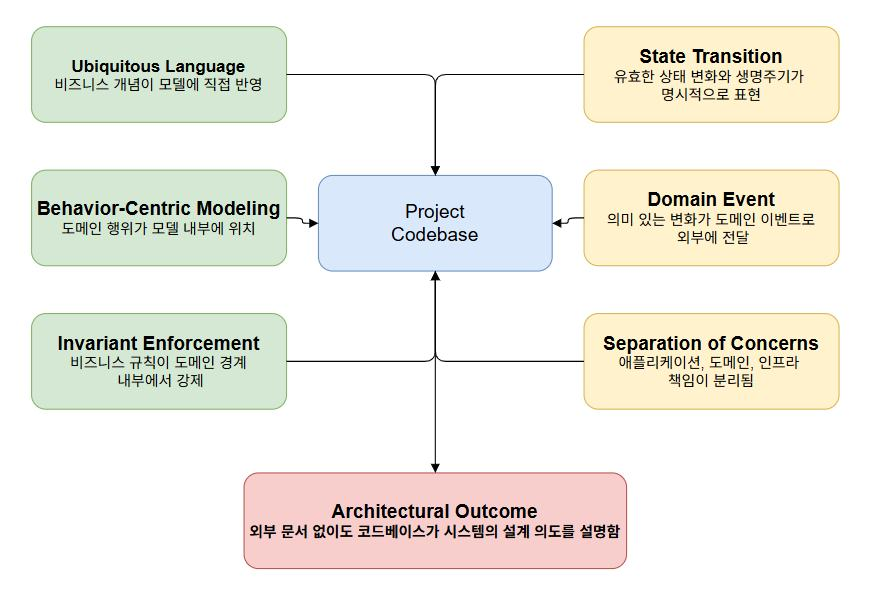
- Bounded Context 및 Aggregate Root를 기준으로 패키지 구조를 설계여 도메인 단위의 변경 범위를 명확히 분리
- 도메인 객체가 유스케이스와 규칙을 직접 표현하도록 구성하여 코드만으로 시스템의 흐름과 설계 의도를 파악 가능한 구조 설계
- 비즈니스 규칙을 엔티티 내부에 캡슐화하는 Rich Domain Model을 적용하여 서비스 레이어에 로직이 분산되는 문제를 방지
주요 기여
화상 시스템 전환 (Jitsi API → WebRTC)
- Jitsi API의 커스터마이징 한계로 WebRTC 기반 P2P 구조로 전환
- 참여도 측정·음성 데이터 수집 등 서비스 고유 기능과의 연동이 전환 이유
- 전용 Signaling 서버를 구현하고 coturn 기반 STUN/TURN 서버를 구축하여 안정적인 P2P 연결을 확보
회의 요약 전환 (Python AI → Spring AI)
- 팀 7명 → 2명 축소에 따라 별도 Python 서버의 운영 부담 증가
- 참여도 측정·음성 데이터 수집 등 서비스 고유 기능과의 연동이 전환 이유
- Spring AI 기반 단일 파이프라인으로 통합해 배포 포인트 제거 및 운영 비용 절감
ArchUnit 아키텍처 테스트
- 아키텍처 설계 원칙이 문서에만 머무르지 않도록 계층 간 의존성과 패키지 규칙을 테스트 코드로 구체화
- 개발 과정에서 발생할 수 있는 설계 위반을 빌드 단계에서 조기에 탐지
- 설계와 구현 간 불일치를 사전에 방지
참여도 산출 모델 설계
- 단순 접속 시간이 아닌 실제 기여도를 반영하기 위해 참여율 산출 모델 설계
- 채팅(0.01)·발화(0.5)·참여시간(0.49) 가중치 기반으로 참여도 계산
- Redis 기반 이벤트 저장 구조를 도입하여 장애 상황에서도 데이터 유실 방지
채팅 시스템
- WebSocket을 통해 실시간 메시지 송수신 처리
- RabbitMQ를 활용해 메시지 전달과 처리를 비동기적으로 분리
- 메시지 수신(WebSocket)과 저장/처리(RabbitMQ Consumer)를 분리하여 서버 장애 상황에서도 메시지 유실 최소화
협업 프로세스 & 문서 관리
- 정기 공유 프로세스와 이슈 트래킹 체계를 도입하여 정보 전달 누락과 작업 중복 문제 개선
- Overview(목표·일정) / Team Docs(운영 규칙) / Tech Docs(아키텍처·API) 3단 구조로 문서 중앙화
- 프로젝트 온보딩 비용 최소화
트러블슈팅
성능 최적화
운영 안정성 확보
회고
이번 Meezy. 프로젝트는 단순히 기술 경험을 넘어, 제가 프로젝트와 개발을 바라보는 관점을 크게 바꾸게 된 경험이었습니다.
Meezy. 프로젝트는 기존 BLIP 프로젝트를 기반으로 현재 서비스 상황과 요구사항에 맞춰 구조를 재설계하며 재개발한 프로젝트입니다. 기존 Jitsi API 기반 구조를 WebRTC 기반으로 전환하면서 실시간 통신 구조를 깊이 있게 학습할 수 있었으며, Python AI Server를 Spring AI Server로 이전하며 운영 효율성과 유지보수성을 함께 고려한 구조 개선을 경험할 수 있었습니다.
프로젝트를 진행하면서 저는 단순히 잘 작동하는 서비스가 좋은 프로젝트라고 생각했던 관점이 바뀌게 된 계기가 되었습니다. 이제는 사용자뿐 아니라 개발자 입장에서도 잘 동작하는 프로젝트가 중요하다고 생각합니다. 사용자는 안정적으로 서비스를 이용할 수 있어야 하고, 개발자는 지속 가능한 코드와 구조 위에서 원활하게 협업할 수 있어야 한다고 느꼈습니다.
특히 이번 프로젝트를 통해 협업 구조의 중요성을 크게 느꼈습니다. 기존 BLIP 프로젝트에서는 문제가 발생했을 때 프론트엔드와 백엔드 간 충분한 소통 없이 각자 해결하려는 방식이 반복되었고, 그 과정에서 일정 지연과 의사결정 문제가 발생했습니다. 결국 AI EXPO에서는 완성된 서비스를 선보이지 못해 아쉬움도 컸지만, 동시에 여러 기업 관계자들로부터 시장성과 가능성에 대한 긍정적인 피드백을 받으며 프로젝트를 다시 제대로 완성해보고 싶다는 동기부여를 얻을 수 있었습니다.
이후 Meezy. 프로젝트에서는 역할 분담, 정기 공유, 이슈 트래킹 체계 등을 새롭게 설계하며 협업 구조를 우선적으로 개선했습니다. 이 경험을 통해 저는 좋은 개발자는 단순히 코드를 잘 작성하는 사람이 아니라, 함께 일하는 개발자들까지 편안하게 만들 수 있는 사람이라고 생각하게 되었습니다.